
AIの進化は止まることを知らず、現在では画像・音声・テキストといった複数の情報を同時に処理できる「マルチモーダルAI」が注目を集めています。これは単なる文字や画像の認識を超え、人間のように複数の情報源を統合して理解・判断するAIです。
マルチモーダルAIとは何か?
マルチモーダルAI(Multimodal AI)とは、テキスト・画像・音声・動画など複数の「モード(情報形式)」を統合して理解・出力する人工知能のことを指します。従来のAIは1つの情報形式に特化していましたが、マルチモーダルAIは複雑な情報を組み合わせることで、より直感的かつ自然なインタラクションが可能になります。
活用が進む分野とその可能性
この技術は、以下のような分野で実用化が進んでいます:
- 医療分野:X線画像とカルテを同時解析する診断支援
- 教育分野:音声・画像を活用したインタラクティブな学習体験
- クリエイティブ分野:テキストと画像を組み合わせたコンテンツ生成
例えば、音声・テキスト・映像を組み合わせた会話型AIの開発も進んでおり、企業のカスタマーサポートや受付システムなどに導入されています。
実際に、V-CUBE社の会話型AIエンジンでは、マルチモーダル技術を活用した自然な対話体験を提供しており、今後の活用例として注目されています。
私たちの生活への影響
こうした技術が私たちの生活にもたらす影響は計り知れません。日常のサポートからエンタメ、教育、医療まで、私たちの行動や選択をより自然にサポートするパートナーとして、AIの役割はますます拡大していくでしょう。
マルチモーダルAIが注目される背景
近年、生成AIの発展により、AIによるアウトプットの精度が飛躍的に向上しました。従来は「文章を生成するAI」「画像を認識するAI」といったように、それぞれのタスクに特化したAIが主流でした。しかし、人間の知覚や思考は、視覚・聴覚・言語といった複数の情報を同時に処理する能力によって成り立っています。
この人間のような情報処理をAIに実現させる試みが、マルチモーダルAIです。ChatGPTやGemini、Claudeなどの大規模言語モデル(LLM)に加えて、画像認識、音声認識、さらには動画理解などの複数のモダリティ(modalities)を組み合わせることで、より高次元の知能を生み出そうという動きが活発になっています。
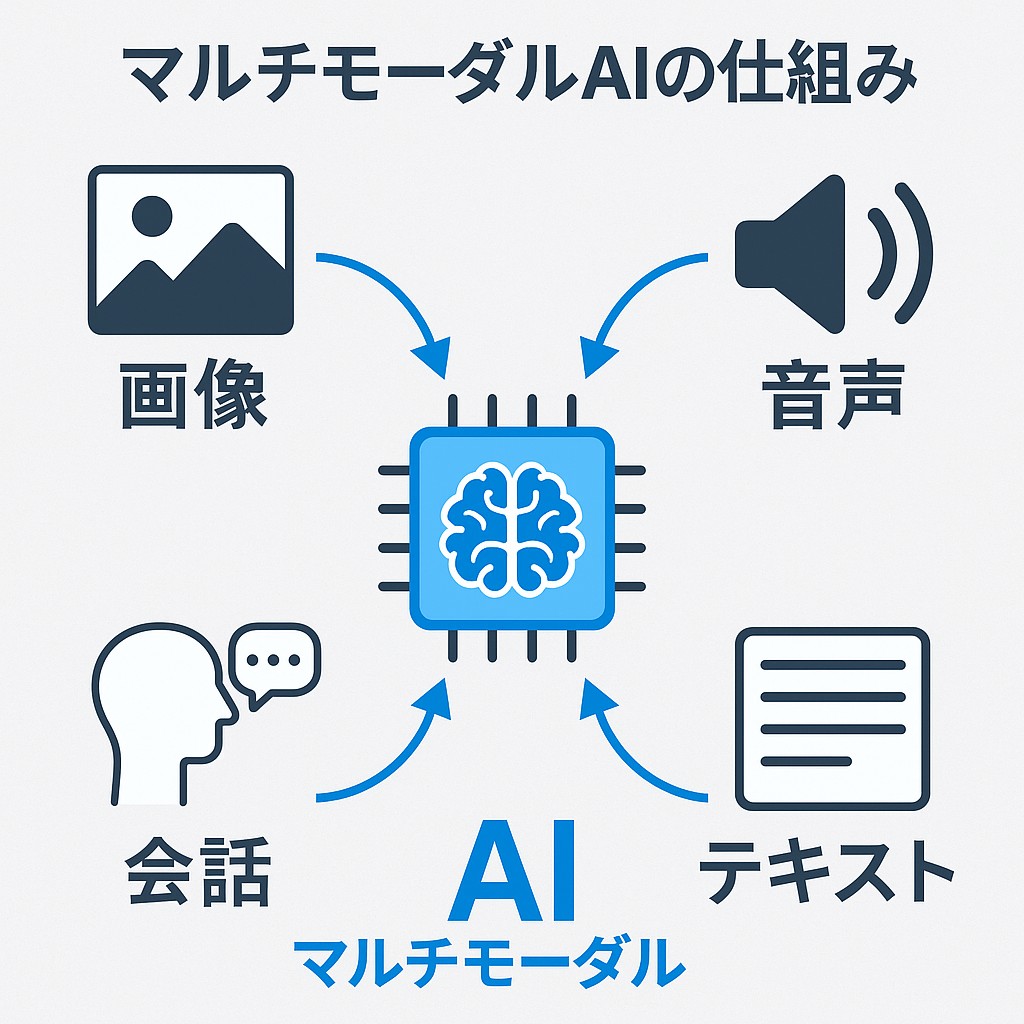
主な技術要素と進化の方向性
マルチモーダルAIを支える代表的な技術には、以下のようなものがあります:
- ビジョン・トランスフォーマー(ViT):画像理解を自然言語処理と同じTransformer構造で行う
- CLIP:画像とテキストの対応関係を学習するモデル(OpenAI)
- Whisper:音声認識モデル。話し言葉を正確にテキストに変換する
- Video Understanding:フレーム間の関係性を捉えるAIモデル
今後はこれらの技術がさらに統合され、動画+音声+テキストを一体で処理するAIアシスタントが、Web検索、教育、医療、そして創作支援など、あらゆる領域で実用化されていくと予想されています。
企業にとっての導入メリット
企業がマルチモーダルAIを導入することで得られるメリットは多数あります。たとえば、商品レビューと画像・動画を統合して分析することで、顧客満足度の向上に貢献できます。また、サポート業務では、問い合わせ内容と顧客の操作画面キャプチャを同時に解析することで、より適切な回答をAIが自動生成できるようになります。
さらに、社内教育やマニュアル整備においても、テキストと画像・音声を併用した学習コンテンツの自動生成が可能となり、人件費や教育コストの削減にもつながります。
個人ユーザーへの影響と日常利用
個人ユーザーにとっても、マルチモーダルAIは日常生活の中で徐々に存在感を増しています。たとえば、スマートフォンのカメラで撮影した画像をAIに解析させて、レシピを提案したり、翻訳したりするような使い方は、今や珍しくありません。
また、障がいを持つ方への支援にも役立っています。音声入力と視線追跡を組み合わせたインターフェースにより、手が不自由な方でもパソコン操作が可能になるなど、テクノロジーの恩恵は幅広い層に届いています。
倫理的課題と今後の展望
一方で、マルチモーダルAIには倫理的な課題も存在します。例えば、画像・映像を扱う場合、個人情報や肖像権の扱いには特に注意が必要です。また、生成される情報の信頼性や偏り、ディープフェイクとの関連など、今後の社会実装には慎重な議論とガイドラインの整備が求められます。
しかし、これらの課題に真摯に向き合いながら技術を進化させることで、私たちは「本当に人に寄り添うAI」との共存を実現できるはずです。
まとめ:マルチモーダルAIの未来
マルチモーダルAIは、まさにAI技術の次なる進化の象徴です。文字、音声、画像、動画といった多様な情報を統合し、より直感的で人間的なインタラクションを可能にします。その応用範囲はビジネスから教育、医療、そして日常生活にまで広がっており、今後の社会に不可欠な存在になることは間違いありません。
生成AI時代において、マルチモーダル技術はもはや”未来”ではなく、”今”の話です。この波に乗り遅れないためにも、私たちはその動向を注視し、活用方法を学び続ける必要があります。
さらに知りたい方へ
マルチモーダルAIをはじめとする生成AIの進化は、ビジネス現場でも活用が広がっています。実際の導入事例に関心がある方は、以下の記事もぜひご覧ください:







コメント